
版权声明:本文由熊训德原创文章,转载请注明出处:
文章原文链接:来源:腾云阁
Hbase的WAL机制是保证hbase使用lsm树存储模型把随机写转化成顺序写,并从内存read数据,从而提高大规模读写效率的关键一环。wal的多生产者单消费者的线程模型让wal的写入变得安全而高效。
在文章《》中从代码层面阐述了一个client的“写”操作是如何到达Hbase的RegionServer,又是如何真正地写入到wal(FSHLog)文件,再写入到memstore。但是hbase是支持mvcc机制的存储系统,本文档将说明RegionServer是如何把多个客户端的“写”操作安全有序地落地日志文件,又如何让client端优雅地感知到已经真正的落地。
wal为了高效安全有序的写入,笔者认为最关键的两个机制是wal中使用的线程模型和多生产者单消费者模型。
线程模型
其线程模型主要实现实在FSHLog中,FSHLog是WAL接口的实现类,实现了最关键的apend()和sync()方法,其模型如图所示:

这个图主要描述了HRegion中调用append和sync后,hbase的wal线程流转模型。最左边是有多个client提交到HRegion的append和sync操作。当调用append后WALEdit和WALKey会被封装成FSWALEntry类进而再封装成RinbBufferTruck类放入一个线程安全的Buffer(LMAX Disruptor RingBuffer)中。当调用sync后会生成一个SyncFuture进而封装成RinbBufferTruck类同样放入这个Buffer中,然后工作线程此时会被阻塞等待被notify()唤醒。在最右边会有一个且只有一个线程专门去处理这些RinbBufferTruck,如果是FSWALEntry则写入hadoop sequence文件。因为文件缓存的存在,这时候很可能client数据并没有落盘。所以进一步如果是SyncFuture会被批量的放到一个线程池中,异步的批量去刷盘,刷盘成功后唤醒工作线程完成wal。
源码分析
下面将从源码角度分析其中具体实现过程和细节。
工作线程中当HRegion准备好一个行事务“写”操作的,WALEdit,WALKey后就会调用FSHLog的append方法:
 FSHLog的append方法首先会从LAMX Disruptor RingbBuffer中拿到一个序号作为txid(sequence),然后把WALEdit,WALKey和sequence等构建一个FSALEntry实例entry,并把entry放到ringbuffer中。而entry以truck(RingBufferTruck,ringbuffer实际存储类型)通过sequence和ringbuffer一一对应。
FSHLog的append方法首先会从LAMX Disruptor RingbBuffer中拿到一个序号作为txid(sequence),然后把WALEdit,WALKey和sequence等构建一个FSALEntry实例entry,并把entry放到ringbuffer中。而entry以truck(RingBufferTruck,ringbuffer实际存储类型)通过sequence和ringbuffer一一对应。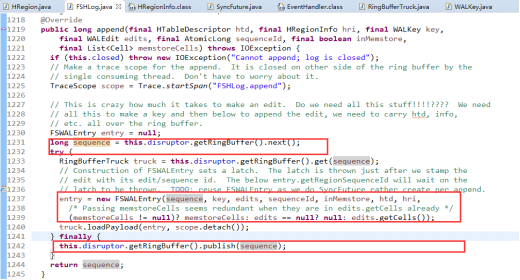 如果client设置的持久化等级是USER_DEFAULT,SYNC_WAL或FSYNC_WAL,那么工作线程的HRegion还将调用FSHLog的sync()方法:
如果client设置的持久化等级是USER_DEFAULT,SYNC_WAL或FSYNC_WAL,那么工作线程的HRegion还将调用FSHLog的sync()方法: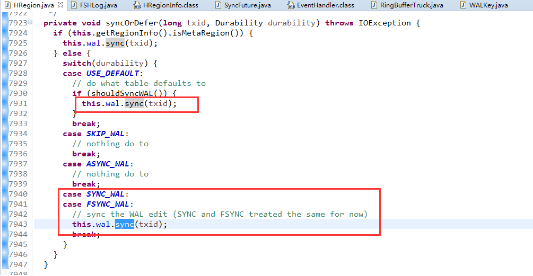
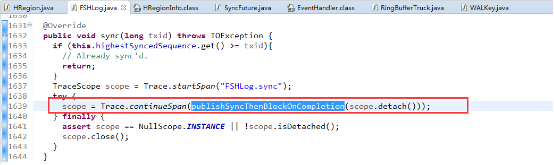

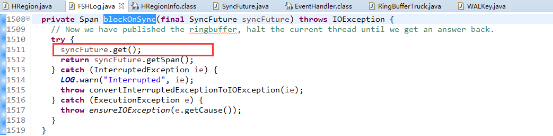
追踪代码可以分析出Sync()方法会往ringbuffer中放入一个SyncFuture对象,并阻塞等待完成(唤醒)。
像模型图中所展示的多个工作线程封装后拿到由ringbuffer生成的sequence后作为生产者放入ringbuffer中。在FSHLog中有一个私有内部类RingBufferEventHandler类实现了LAMX Disruptor的EventHandler接口,也即是实现了OnEvent方法的ringbuffer的消费者。Disruptor通过 java.util.concurrent.ExecutorService 提供的线程来触发 Consumer 的事件处理,可以看到hbase的wal中只启了一个线程,从源码注释中也可以看到RingBufferEventHandler在运行中只有单个线程。由于消费者是按照sequence的顺序刷数据,这样就能保证WAL日志并发写入时只有一个线程在真正的写入日志文件的可感知的全局唯一顺序。
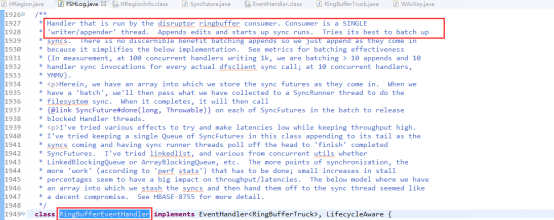 RingBufferEventHandler类的onEvent()(一个回调方法)是具体处理append和sync的方法。在前面说明过wal使用RingBufferTruck来封装WALEntry和SyncFuture(如下图源码),在消费线程的实际执行方法onEvent()中就是被ringbuffer通知一个个的从ringbfer取出RingBufferTruck,如果是WALEntry则使用当前HadoopSequence文件writer写入文件(此时很可能写的是文件缓存),如果是SyncFuture则简单的轮询处理放入SyncRunner线程异步去把文件缓存中数据刷到磁盘。这里再加一个异步操作去真正刷文件缓存的原因wal源码中有解释:刷磁盘是很费时的操作,如果每次都同步的去刷client的回应比较快,但是写效率不高,如果异步刷文件缓存,写效率提高但是友好性降低,在考虑了写吞吐率和对client友好回应平衡后,wal选择了后者,积累了一定量(通过ringbuffer的sequence)的缓存再刷磁盘以此提高写效率和吞吐率。这个决策从hbase存储机制最初采用lsm树把随机写转换成顺序写以提高写吞吐率,可以看出是目标一致的。
RingBufferEventHandler类的onEvent()(一个回调方法)是具体处理append和sync的方法。在前面说明过wal使用RingBufferTruck来封装WALEntry和SyncFuture(如下图源码),在消费线程的实际执行方法onEvent()中就是被ringbuffer通知一个个的从ringbfer取出RingBufferTruck,如果是WALEntry则使用当前HadoopSequence文件writer写入文件(此时很可能写的是文件缓存),如果是SyncFuture则简单的轮询处理放入SyncRunner线程异步去把文件缓存中数据刷到磁盘。这里再加一个异步操作去真正刷文件缓存的原因wal源码中有解释:刷磁盘是很费时的操作,如果每次都同步的去刷client的回应比较快,但是写效率不高,如果异步刷文件缓存,写效率提高但是友好性降低,在考虑了写吞吐率和对client友好回应平衡后,wal选择了后者,积累了一定量(通过ringbuffer的sequence)的缓存再刷磁盘以此提高写效率和吞吐率。这个决策从hbase存储机制最初采用lsm树把随机写转换成顺序写以提高写吞吐率,可以看出是目标一致的。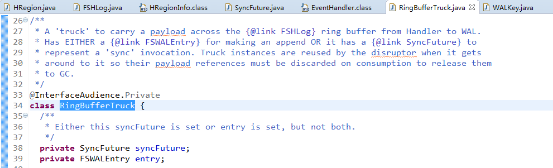 这部分源码可以看到RingBufferTruck类的结构,从注释可以看到选择SyncFuture和FSWALEntry一个放入ringbuffer中。
这部分源码可以看到RingBufferTruck类的结构,从注释可以看到选择SyncFuture和FSWALEntry一个放入ringbuffer中。 这部分源码可以看到append的最终归属就是根据sequence有序的把FSWALEntry实例entry写入HadoopSequence文件。这里有序的原因是多工作线程写之前通过ringbuffer线程安全的CAS得到一个递增的sequence,ringbuffer会根据sequence取出FSWALEntry并落盘。这样做其实只有在得到递增的sequence的时候需要保证线程安全,而java的CAS通过轮询并不用加锁,所以效率很高。具体有关ringbuffer说明和实现可以参考LMAX Disruptor文档:
.
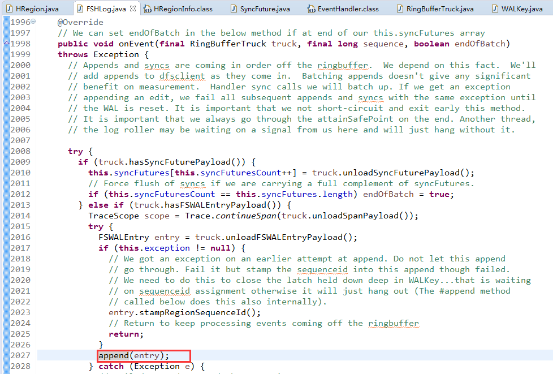
这部分源码是说明sync操作的SyncFuture会被提交到SyncRunner中,这里可以注意SyncFuture实例其实并不是一个个提交到SyncRunner中执行的,而是以syncFutures(数组,多个SyncFuture实例)方式提交的。下面这部分源码是注释中说明批量刷盘的决策。
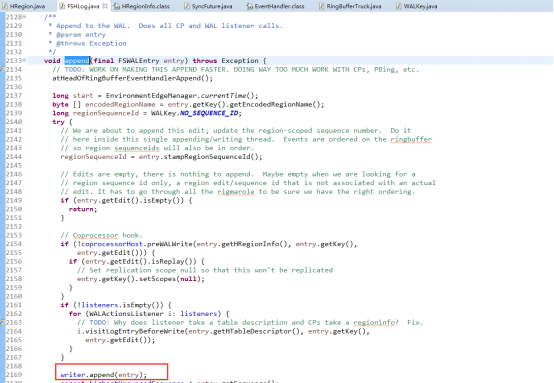
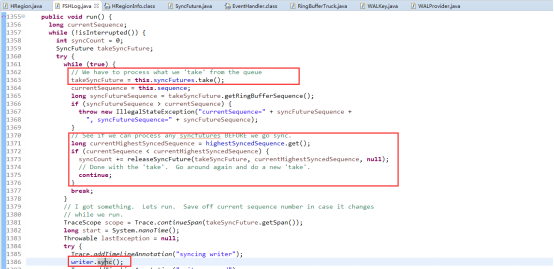
SyncRunner是一个线程,wal实际有一个SyncRunner的线程组,专门负责之前append到文件缓存的刷盘工作。


SyncRunner的线程方法(run())负责具体的刷写文件缓存到磁盘的工作。首先去之前提交的synceFutues中拿到其中sequence最大的SyncFuture实例,并拿到它对应ringbuffer的sequence。再去比对当前最大的sequence,如果发现比当前最大的sequence则去调用releaseSyncFuture()方法释放synceFuture,实际就是notify通知正被阻塞的sync操作,让工作线程可以继续往下继续。前面解释了sequence是根据提交顺序过来的,并且解释了append到文件缓存的时候也是全局有序的,所以这里取最大的去刷盘,只要最大sequence已经刷盘,那么比这个sequence的也就已经刷盘成功。最后调用当前HadoopSequence文件writer刷盘,并notify对应的syncFuture。这样整个wal写入也完成了。
小结
Hbase的WAL机制是保证hbase使用lsm树存储模型把随机写转化成顺序写,并从内存read数据,从而提高大规模读写效率的关键一环。wal的多生产者单消费者的线程模型让wal的写入变得安全而高效,本文档从源码入手分析了其线程模型为以后更好开发和研究hbase其他相关知识奠定基础。